Quick overview of AIWhispr design
- Arun Prasad

- Aug 30, 2023
- 4 min read
AIWhispr takes a modular design approach, recognising that 4 distinct functions are coordinated to drive a scalable semantic search engine. This approach helped us quickly scale up to build a demo which processes over 1 million askubuntu.com posts downloaded from Internet Archive.
Semantic Search Engine process overview
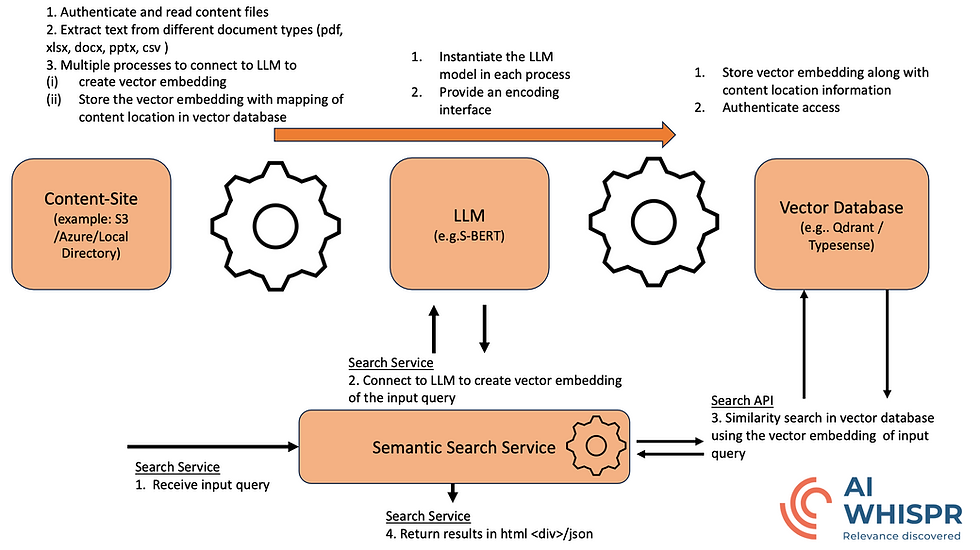
Content site handler : It can access cloud storage (AWS S3 bucket, Azure blob) or local directory path to read files. It will then extract text from different document types (pdf, xlsx, docx, pptx, csv ) , create vector embeddings by submitting the text chunk to a large language model encoding service. The vector embedding and related metadata of the file is stored in a vector database. It scales up by spawning multiple processes to distribute this workload.
Large Language Model is primarily responsible for creating vector embedding.
Vector Database that stores the vector embedding for the file content along with metadata related to the file e.g. location, size, last edited date; it should support vector similarity searches on the stored vector data.
Semantic Search Service - a programmatic interface that accepts a user query e.g. "what is the best computer to buy for an affordable price?", converts it into a vector embedding and then runs a similarity search in the vector database to retrieve the results (vector and corresponding text, file meta data). It formats these retrieved results into html<div> or json and responds to the user query.
AIWhispr design philosophy is that a no/low-code deployment with simple configuration makes it easy to start your semantic search journey. You can then add your own content, llm, vector database handlers in AIWhispr to customise for your requirements.

An AIWhispr configuration file exhibits this modular design approach.
A typical configuration file looks like:
#### CONFIGFILE ####
[content-site]
sitename=example_bbc.filepath.qdrant
srctype=filepath
srcpath=/<aiwhispr_home>/aiwhispr/examples/http/bbc
displaypath=http://127.0.0.1:9000/bbc
contentSiteModule=filepathContentSite
[content-site-auth]
authtype=filechecks
check-file-permission=Y
[local]
indexing-processes=2
working-dir=/<aiwhispr_home>/aiwhispr/examples/http/working-dir
index-dir=/<aiwhispr_home>/aiwhispr/examples/http/working-dir
[vectordb]
vectorDbModule=qdrantVectorDb
api-address= localhost
api-port=6333
api-key=
[llm-service]
model-family=sbert
model-name=all-mpnet-base-v2
llm-service-api-key=
llmServiceModule=libSbertLlmService
Overview of the configuration file
The configuration file has 5 sections
[content-site]
This section contains the configurations for the content source from which AIWhispr will read the files which have to be indexed.
sitename=<unique_name>
It cannot contain whitespace, special characters except '.'
srctype=<filepath / s3 / azureblob >
filepath: top level local or mounted directory path
s3 : Content source is an AWS S3 bucket
azureblob: Content source is an Azure blob container
srcpath=<top_level_path_which_AIWhispr_will_start_reading>
Example AWS S3:
s3//<bucket_name>
Example Azure Blob https://<storage_account>.blob.core.windows.net/<container_name>
displaypath = <top level path that AIWhispr will use when returning the search results>
Example : you can save all your files under the Nginx http root.
A file could be /var/www/html/index_this_file.pdf
-----------------------------
srctype=filepath
srcpath=/var/www/html
displaypath=http:<hostname>
-----------------------------
When the search results are displayed, the top level path is http://<hostname>/index_this_file.pdf
contentSiteModule=<awsS3ContentSite / azureContentSite /
filepathContentSite >
You can add custom content site handler python modules under $AIWHISPR_HOME/python/content-site directory and configure them.
doNotReadDirList=<A comma separated directory list that should not be read>
If srctype=filepath then the full path to the directory.
example:
doNotReadDirList=/var/www/html/bbc/sport, /mydocs/confidential
Dont include the Bucket/Container name at the top level when srctype=s3 or srctype=azureblob
doNotReadFileList=<A comma separated filename,filename pattern list that should not be read>
example:
doNotReadFileList=*.log.txt, *.test.docx
The python modules for content-site are under $AIWHISPR_HOME/python/content-site
[site-auth]
In this section you configure the authentication for the source (S3 bucket/Azure blob container) from which files will be read.
authtype=< filechecks / aws-key / sas / az-storage-key >
Authentication credentials required to access the content source.
filechecks : specify this when srctype=filepath,
sas : when using Azure SAS token
az-storage-key: when using Azure Storage Key
aws-key: AWS S3 (Signed / Unsigned) access
key=<Specify the key value when authtype=aws-key/az-storage-key>
configure key=UNSIGNED to access AWS S3 buckets that allow unsigned access.
sastoken=<Azure SAS Token: applicable when authtype=sas>
[local]
This section is used to configure the path to local directories that AIWhispr can use for its content indexing processes and to configure how many processes should be started in parallel to distribute the workload.
working-dir=<local_directory>
AIWhispr requires a local working directory o work with extracted text.
index-dir=<local_directory>
A directory where AIWhispr will store a local SQLite3 database o store content metadata which is used when indexing the content.
indexing-processes=<integer:should_be_1_or_less_than_no_of_cpu>
indexing-processes is configured to an integer value 1 or greater. It should not be greater than the number of CPUs on the machine. AIWhispr spawns multiple processes using this value.
Spawning of multiple indexing processes is effective when you have GPUs for LLM and multiple CPUs.
If you have only CPUs then this should be set to 1 or 50% of the CPUs on the machine to ensure you have enough CPUs for other processes.
Example: on a 4 CPU machine, configure indexing-processes=2[vectordb]
A section to configure the vector database access.
api-address=<vectordb-api-adress>
api-port=<vectordb-api-port>
api-key=<vectordb-api-key>
vectorDbModule=< qdrantVectorDb / typesenseVectorDb >
You can add custom vector database handler python modules under the directory $AIWHISPR_HOME/python/vectordb and configure them.[llm-service]
A section to configure the large-language-model (LLM) used to create the vector embedding. AIWhispr uses sentence-transformer library.
You can customize this by writing your own LLM encoding handler under $AIWHISPR_HOME/python/llm-service
The default configuration is:
[llm-service]
model-family=sbert
model-name=all-mpnet-base-v2
llm-service-api-key=
llmServiceModule=libSbertLlmServiceAdding custom content site, large language model, vector database python modules
AIWhispr team is building integration modules to connect with more content storage sources, large language models, vector databases, making them available through simple configurations with no/low-code.
The modular approach enables you to build custom integrations. An example could be an internal content stored in a proprietary database or format. You can go through one of the existing content site handler python module code in $AIWHISPR_HOME/python/content-site and use it as a template to write your own custom module
example: myCustomContentSite.py
You can then configure the [content-site] section as
[content-site]
contentSiteModule=myCustomContentSite
....
....Please note that the python file suffix .py should not be included.

The ability to integrate custom modules was demonstrated when we had to quickly scale up to process over 1 million askubuntu.com posts downloaded from Internet Archive. The gzip archive has a single Posts.xml file with over 1 million posts.
We added a module "stackexchangeContentSite.py" , configured
srcpath=<aiwhispr_home>/examples/askubuntu/Posts.xml
and started the indexing process with multiple processes.



Comments